Abstract
Method Overview
we propose a novel attention mechanism called Multi-Frequency in Multi-Scale Attention (MFMSA) block. This block employs multi-frequency channel attention (MFCA) with 2D Discrete Cosine Transform (2D DCT) to produce a channel attention map by extracting frequency statistics. Subsequently, multi-scale spatial attention (MSSA) is applied to extract discriminative boundary features and aggregate them from each scale. Additionally, we introduce a Ensemble Sub-Decoding Module (E-SDM) to prevent information loss caused by drastic upsampling during multi-task learning with deep supervision. The resulting model, MADGNet, which mainly comprises the MFMSA block and E-SDM, achieved the highest segmentation performance in various modalities and clinical settings.
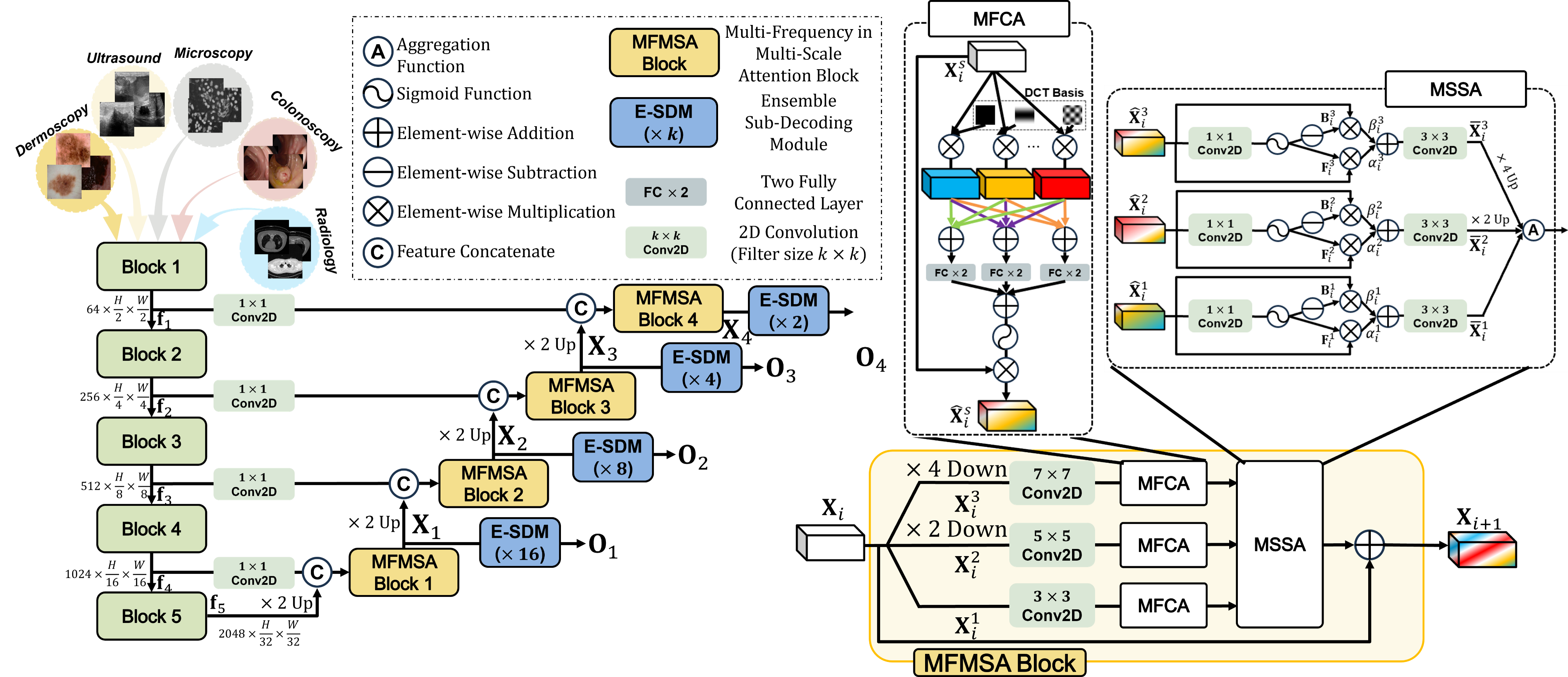
Figure 1: (Left) The overall architecture of the proposed MADGNet mainly comprises MFMSA block and E-SDM. (Right) MFMSA block contains $S$ scale branches ($S = 3$ in this figure) where the $s$-th branch input feature map are downsampled into $\eta^{s - 1}$ ($\eta = \frac{1}{2}$ in this figure). As our MFMSA block considers two dimensions (scale and frequency), MADGNet achieves the highest performance in various modalities and other clinical settings. Additionally, since E-SDM predicts a core task from sub-tasks, the final output is more accurate than when processed parallelly.
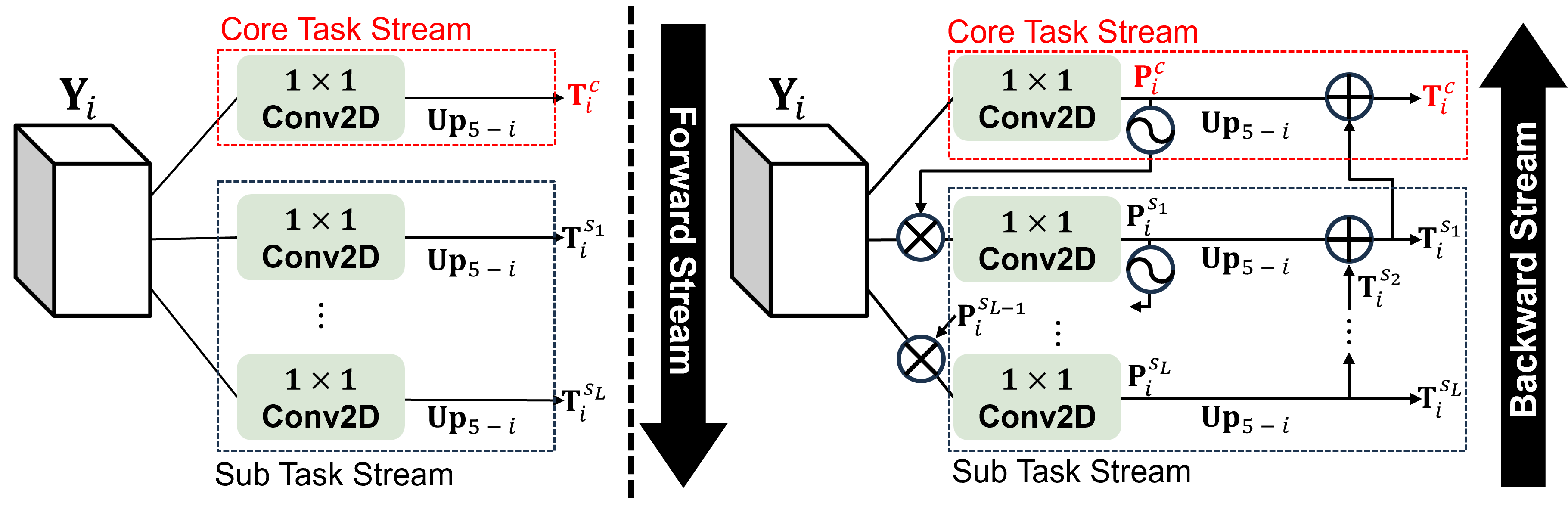
Figure 2: Comparison of multi-task learning method between (Left) parallel and (Right) ensemble manners.
SOTA Comparison with Quantitative Results
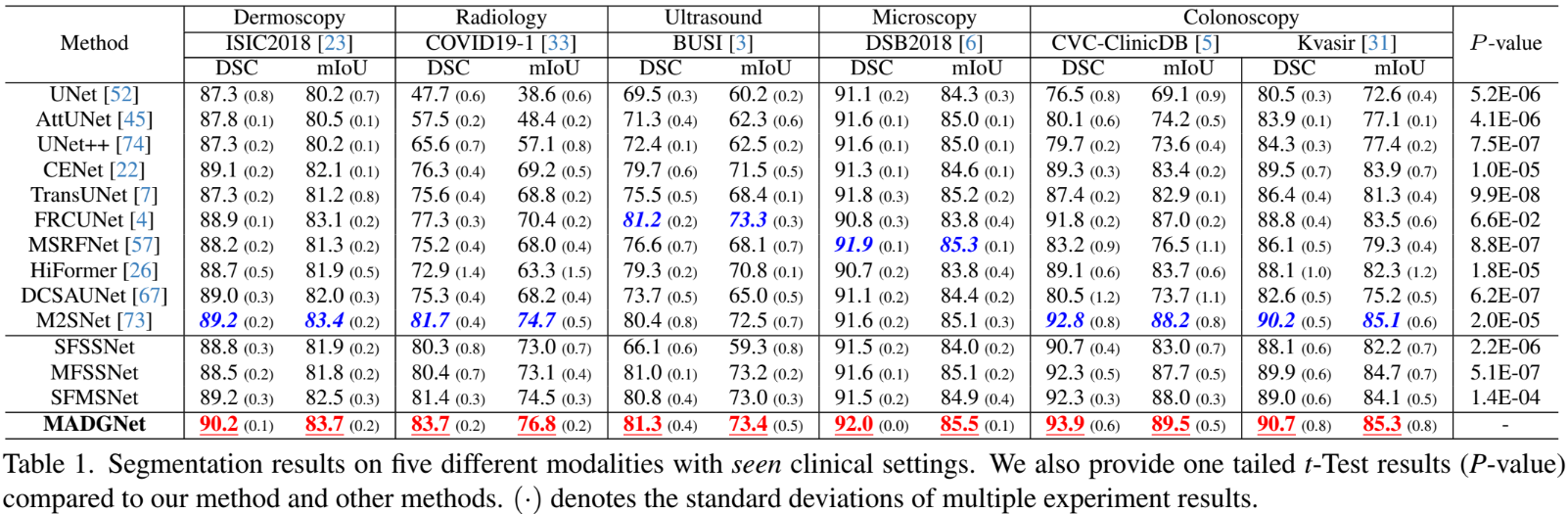
Comparison on Seen Clinical Settings
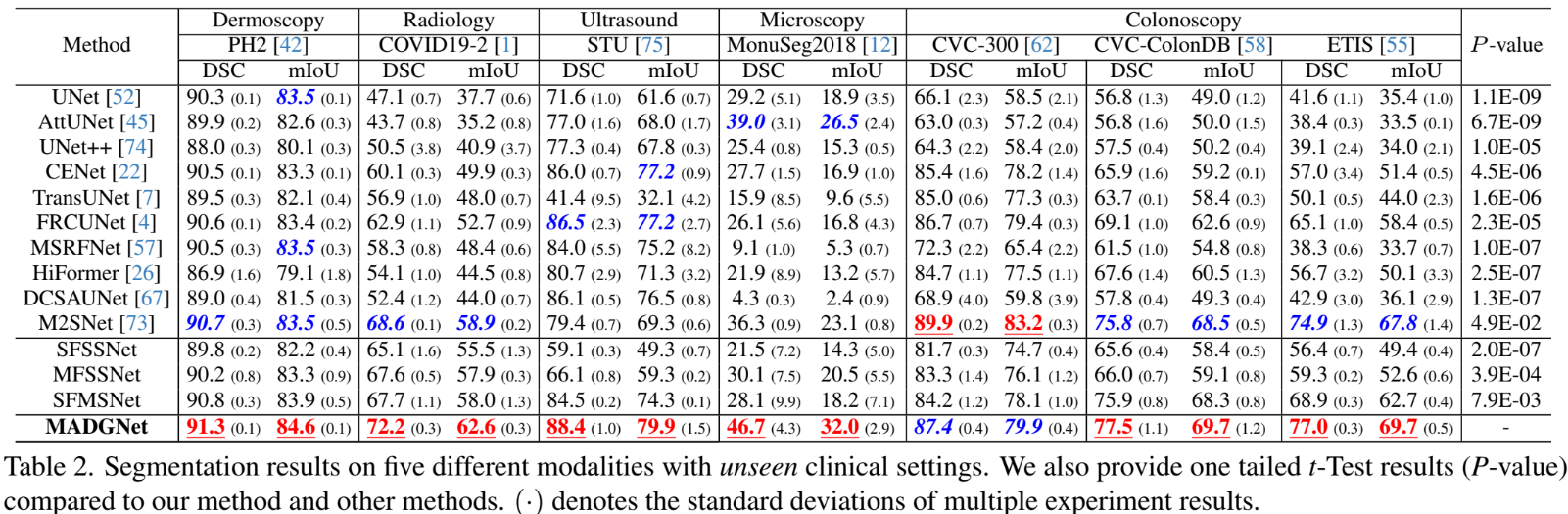
Comparison on Unseen Clinical Settings
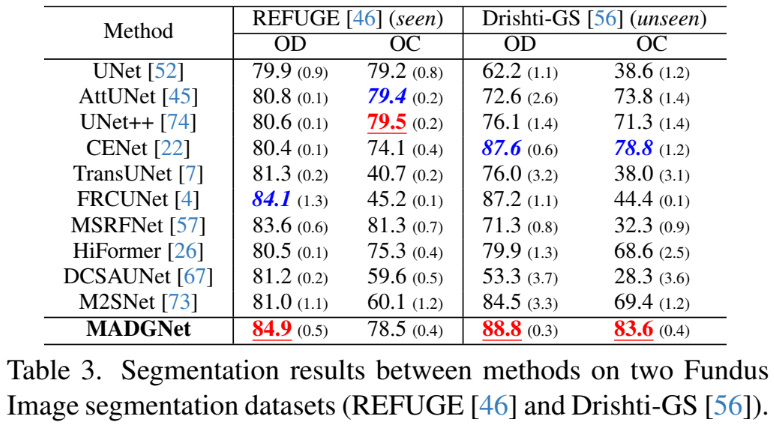
Comparison on Fundus Segmentation
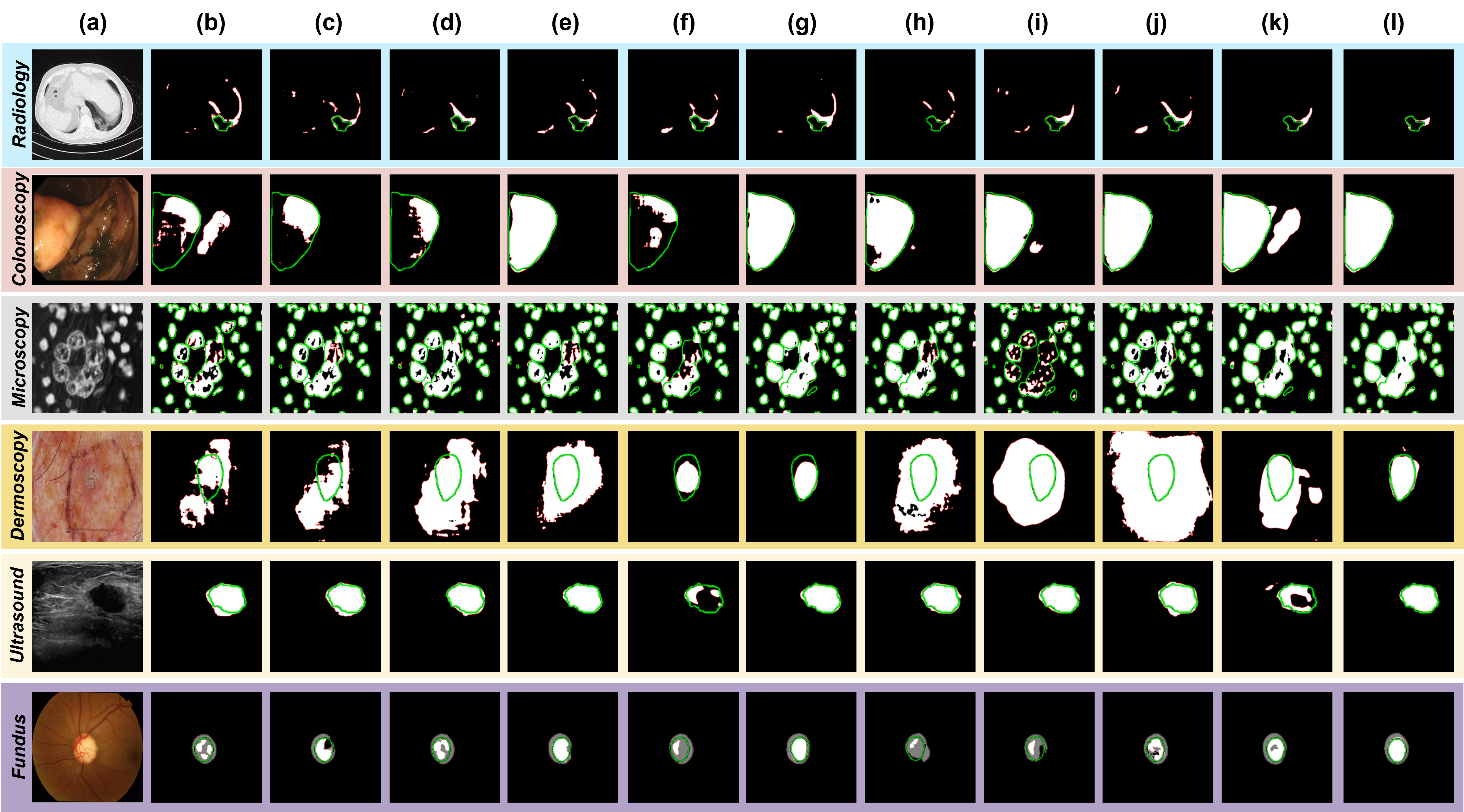
SOTA Comparison with Qualitative Results
BibTeX
Acknowledgement
This work was supported in part by the National Research Foundation of Korea (NRF) under Grant NRF-2021R1A2C2010893 and in part by Institute of Information and communications Technology Planning \& Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2022-00155915, Artificial Intelligence Convergence Innovation Human Resources Development (Inha University).